Yinelenen Sinir Ağları (RNN), verilerin önceki bilgilerine bağlı olarak çalışan bir makine öğrenimi modelidir. Bu model, özellikle doğal dil işleme, metin üretimi, zaman serisi verileri ve diğer sürekli veriler gibi zamanla değişen verilerin işlenmesinde kullanılır.
RNN’ler, birbirleriyle bağlantılı hücrelerin (neuronlar) oluşturduğu bir ağdır. Bu hücreler, hem girdileri hem de önceki çıktıları kullanarak yeni bir çıktı üretirler. RNN’lerin özelliği, girdilerin ve çıktıların zamanla değişebilmesidir, bu nedenle bu model, zaman serileri verileri gibi sıralı verileri işlemek için uygundur.
RNN’lerin temel bileşeni, hücre olarak adlandırılan bir yapıdır. Hücreler, iç durumlarını koruyarak girdileri ve önceki çıktıları işlerler. RNN’ler, her zaman adımında bu hücreleri kullanır ve bu hücrelerin çıktıları bir sonraki adımın girdisi olarak kullanılır.
RNN’lerin bir diğer önemli bileşeni, geriye doğru besleme (backpropagation) algoritmasıdır. Bu algoritma, hatanın kaynağını belirlemek ve ağın parametrelerini (ağırlıklar ve eşikler) optimize etmek için kullanılır. Geriye doğru besleme, ağın eğitimi sırasında hatanın azaltılması için önemlidir.
RNN’lerin bir diğer varyasyonu, uzun-kısa süreli bellek (LSTM) ağlarıdır. LSTM’ler, RNN’lerin aksine, daha uzun vadeli bağımlılıkları işleyebilirler. Bu, LSTM’leri, daha karmaşık zaman serisi verileri gibi uzun vadeli bağımlılıkları olan verileri işlemek için uygundur.
RNN’ler, özellikle doğal dil işleme, dil modelleme ve metin oluşturma gibi alanlarda yaygın olarak kullanılmaktadır. Ayrıca, RNN’ler, yapay zeka, robotik, oyunlar ve diğer birçok uygulama alanında da kullanılmaktadır.

RNN ile Spam Filtresi
Recurrent Neural Network (RNN), bir makine öğrenimi algoritmasıdır ve özellikle zaman serileri gibi sıralı verilerin analizi için kullanılmaktadır. Spam filtresi, istenmeyen e-postaları tespit etmek için kullanılan bir filtreleme sistemidir. RNN’nin sıralı verileri analiz etme özelliği, spam filtreleme sistemlerinde kullanılmasını mümkün kılar.
Spam filtreleri, gelen e-postaların içeriğini analiz ederek, belirli kriterlere göre spam olarak tanımlanan e-postaları tespit etmektedir. Ancak, spam filtreleri bazen istenmeyen e-postaları da spam olarak tanımlayabilir ve bu durum kullanıcılarda hoşnutsuzluk yaratabilir. RNN, bu sorunu çözmek için kullanılabilmektedir.
RNN, gelen e-postaların içerisindeki kelimeleri bir zaman serisi olarak ele alabilir. Her kelime, önceki kelimelerden ve önceki zaman adımlarından gelen bilgilerle birlikte analiz edilir. Bu sayede, RNN, her kelimenin içeriği ve anlamını daha iyi anlayabilir ve gelen e-postaları daha doğru bir şekilde sınıflandırabilir.
RNN’nin kullanılmasıyla, spam filtreleri daha doğru hale getirilebilir ve kullanıcıların istenmeyen e-postaları daha az alması sağlanabilir. Ayrıca, RNN, e-posta içeriğinin yanı sıra gönderenin adresi ve konusu gibi diğer faktörleri de analiz edebilir. Böylece, spam filtresi daha geniş bir veri kümesine dayanarak spam e-postalarını tespit edebilir.
Sonuç olarak, RNN, spam filtreleri için çok faydalı bir araçtır. Gelen e-postaların içeriğinin yanı sıra, gönderenin adresi, konusu ve zamanı gibi diğer faktörlerin de analiz edilmesiyle, spam filtresi daha doğru hale getirilebilir. Bu sayede, kullanıcılar istenmeyen e-postalarla daha az karşılaşabilir ve daha iyi bir e-posta deneyimi yaşayabilirler.
LSTM Nedir?
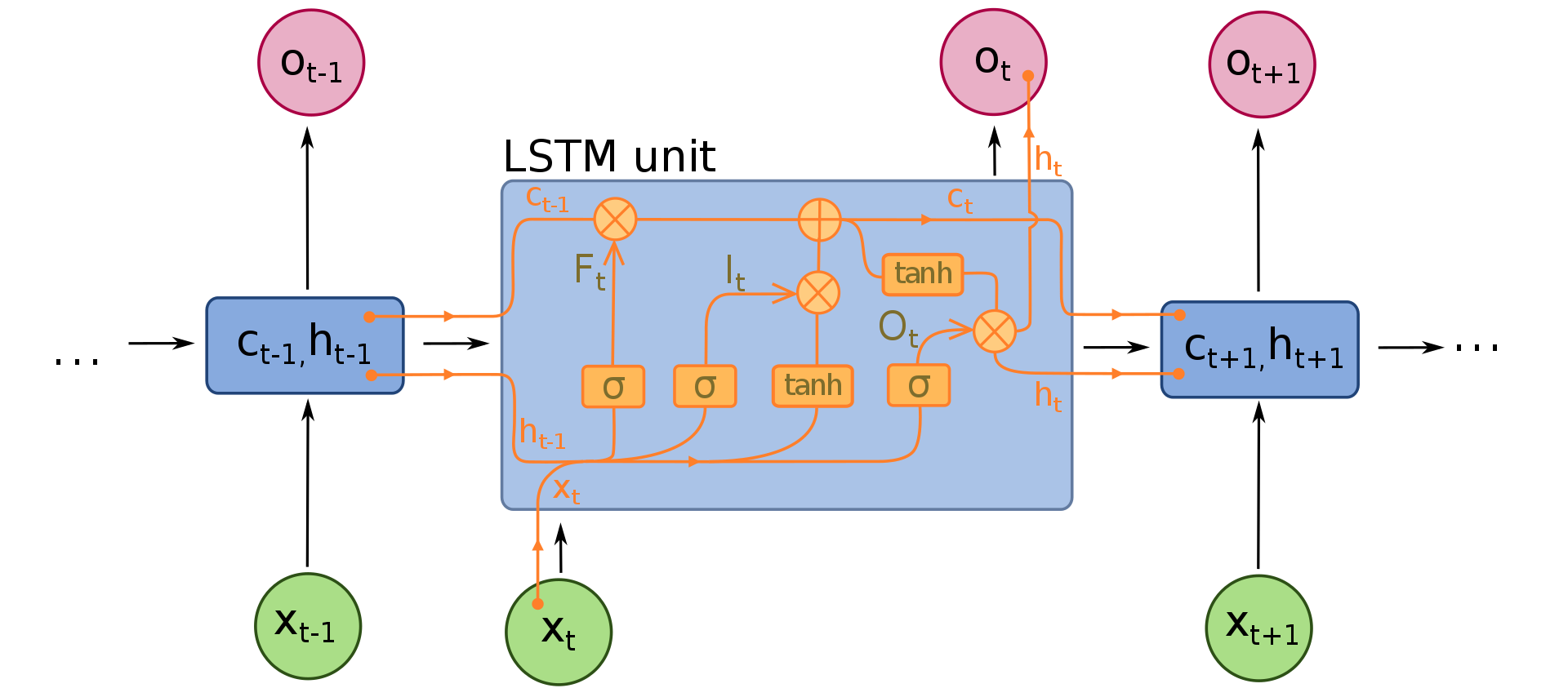
Uzun Kısa-Term Hafıza (LSTM), Recurrent Neural Network (RNN) mimarisi içinde kullanılan bir tür hücredir. LSTM, sıralı verilerin analizi için kullanılır ve özellikle zaman serileri gibi uzun süreli bağımlılıklar içeren verilerin işlenmesinde etkilidir.
LSTM hücresi, girdi, çıktı ve unutma kapılarından oluşan bir mekanizma ile donatılmıştır. Girdi kapısı, yeni verilerin LSTM hücresine giriş yapmasını sağlar. Unutma kapısı, hücre içindeki bilginin ne kadarının unutulacağını belirler. Çıktı kapısı, LSTM hücresindeki bilgiyi, sonraki zaman adımlarına taşımak üzere diğer hücrelere aktarır.
LSTM hücreleri, önceki zaman adımlarında tutulan bilgileri, gelecekteki tahminlerde kullanabildiği için, RNN mimarisindeki basit hücrelere göre daha etkilidir. LSTM, zaman serilerindeki uzun vadeli bağımlılıkları yakalayabilme özelliği ile bilinir ve bu nedenle, dil modelleri, makine çevirisi ve müzikal kompozisyon gibi alanlarda sıklıkla kullanılır.

LSTM, girdi olarak sıralı verileri alır ve önceki zaman adımlarında tutulan bilgileri hatırlayarak, gelecekteki tahminleri yapar. Bu sayede, LSTM, karmaşık sıralı verileri işlemede oldukça başarılıdır. LSTM, ayrıca, düzenlileştirme teknikleri ile birleştirildiğinde, daha az eğitim verisi ile daha iyi sonuçlar elde edebilir.
Sonuç olarak, LSTM, RNN mimarisi içinde kullanılan bir hücre türüdür ve uzun vadeli bağımlılıklar içeren sıralı verilerin analizinde oldukça etkilidir. LSTM hücreleri, önceki zaman adımlarında tutulan bilgileri hatırlayabilme özelliği ile bilinir ve dil modelleri, makine çevirisi ve müzikal kompozisyon gibi alanlarda yaygın olarak kullanılır.
LSTM ile Kelime Üretimi
LSTM (Long Short-Term Memory), dil modellerinde ve doğal dil işlemede sıkça kullanılan bir tür RNN (Recurrent Neural Network) yapısıdır. LSTM, sıralı verilerin analizi için kullanılan bir yapay sinir ağıdır ve uzun vadeli bağımlılıkları ele almak için özel olarak tasarlanmıştır.
Kelime üretimi, dil modellerinin önemli bir uygulamasıdır ve LSTM de bu alanda sıkça kullanılmaktadır. LSTM, kelime üretimi için sıralı verilerin analizi yapar ve ardından yeni kelime öbekleri oluşturur.
LSTM, kelime üretimi için öncelikle bir örnek veri kümesi üzerinde eğitilir. Bu veri kümesindeki kelimeler, LSTM’e sıralı olarak verilir ve her bir kelimenin ardından bir sonraki kelime tahmin edilir. Bu süreç, birçok örnek veri üzerinde tekrarlanarak LSTM’in doğruluğu arttırılır.
Kelime üretimi için LSTM, veri kümesindeki örneklerin analiz edilmesi ve ardından yeni kelime öbeklerinin oluşturulması için kullanılır. Örneğin, bir metin veri kümesinde eğitilen bir LSTM, “Merhaba, nasılsın?” gibi bir girdi aldığında, bu girdiyi analiz eder ve ardından bir sonraki kelimenin “Ben” olabileceğini tahmin edebilir. Bu tahmin, bir sonraki kelime için olasılıkları hesaplayan bir olasılık dağılımı olarak ifade edilir.
LSTM, kelime üretimindeki en büyük avantajı, sıralı verilerde uzun vadeli bağımlılıkları ele alabilmesidir. Bu sayede, bir cümle içindeki kelime sıralamasını doğru bir şekilde tahmin edebilir ve yeni kelime öbekleri oluşturabilir.
LSTM Kelime Üretimi Veri Kümesi
LSTM ile kelime üretimi için, eğitim veri kümesi olarak büyük bir metin belgesi kullanılır. Bu metin belgesi, kelime dizilerinden oluşur ve LSTM modeli tarafından analiz edilerek, kelime üretiminde kullanılmak üzere modelin öğrenmesi sağlanır.
Metin belgesi, öncelikle düzenlenir ve kelime dizilerine ayrılır. Her kelime, benzersiz bir sayısal kimliğe sahip olacak şekilde kodlanır. LSTM modeli, bu sayısal kimlikleri kullanarak, belirli bir kelimenin verilmesi durumunda, bir sonraki kelimeyi tahmin eder.
LSTM modeli, öncelikle bir dizi örnekle eğitilir. Her örnek, belirli bir kelime dizisinin bir bölümünü içerir ve model, önceki kelimeleri kullanarak sonraki kelimeyi tahmin eder. Bu işlem, metin belgesindeki tüm kelime dizileri için tekrarlanır.
Eğitim veri kümesindeki kelime dizileri, model tarafından analiz edilerek, modelin kelime dizilerinin yapısını anlamasına ve doğru bir şekilde bir sonraki kelimeyi tahmin etmesine yardımcı olur. Eğitim süreci tamamlandıktan sonra, model, verilen bir kelime dizisindeki son kelimeyi kullanarak, bir sonraki kelimeyi üretebilir.
LSTM ile kelime üretimi, doğal dil işleme alanında oldukça faydalıdır. Örneğin, bu yöntemle, otomatik metin tamamlama, otomatik özetleme ve hatta konuşma sentezi gibi uygulamalar geliştirilebilir.
Çok Layerlı LSTM ile Harf Üretimi
Çok katmanlı LSTM ağları, doğal dil işleme gibi sıralı verilerin işlenmesi için yaygın olarak kullanılan bir derin öğrenme yöntemidir. Harf üretimi, bir karakter dizisindeki her karakterin ardından gelen karakterleri tahmin etmek için kullanılan bir uygulamadır. Bu uygulama, doğal dil işlemede kelime üretimine benzer, ancak daha düşük seviyede gerçekleştirilir.
Çok katmanlı LSTM ağları, harf üretimi için kullanıldığında, her adımda bir karakter oluşturmak için önceki karakterlere dayalı olarak bir olasılık dağılımı hesaplar. Bu dağılım, her bir karakter için olası sonraki karakterlerin olasılıklarını içerir. Bu olasılıklar, ağın öğrenme süreci sırasında öğrenilir ve her katmanın çıktısı bir sonraki katmana beslenir.
Veri kümesi olarak, bir metin belgesi kullanılabilir.Bu belge, ağın öğrenmesi ve harf üretimi yapması için gerekli olan tüm bilgileri içermelidir.Ağ, bu belgeyi bir karakter dizisi olarak alır ve ardından her karakteri bir vektöre dönüştürür.Bu vektörler daha sonra ağda işlenir ve bir sonraki karakterin olasılık dağılımı hesaplanır.Ağın eğitimi sırasında, belirli bir karakter dizisi girilir ve her karakterden sonra gelen karakterlerin olasılıkları hesaplanır.Bu olasılıkların kullanılmasıyla, ağın tahminleri gerçek değerlerle karşılaştırılır ve ağı güncellemek için geriye doğru bir hata sinyali hesaplanır.Bu işlem, ağın doğru olasılıkları hesaplamasını öğrenmesine yardımcı olur ve ağın performansını geliştirir.