Göğüs kanseri sınıflandırması, makine öğrenimi algoritmalarının kullanıldığı bir tıbbi uygulamadır. Bu uygulama, göğüs kanseri tarama testlerinde elde edilen görüntülerin analiz edilmesi yoluyla kanser türünün saptanmasını amaçlamaktadır. Göğüs kanseri, kadınlarda en sık görülen kanser türlerinden biridir ve erken teşhis edilmesi hayat kurtarıcı olabilir.
Göğüs kanseri sınıflandırması, görüntü işleme teknikleri, özellik çıkarımı ve sınıflandırma algoritmalarının bir arada kullanılmasını gerektirir. Öncelikle, göğüs kanseri tarama testlerinde elde edilen görüntülerin işlenmesi ve ön işlemesi yapılır. Daha sonra, görüntülerden özellikler çıkarılır ve bu özellikler kullanılarak kanser türü belirlenmeye çalışılır.
Sınıflandırma algoritmaları, elde edilen özellikleri kullanarak kanser türünü sınıflandırır.
Makine öğrenimi algoritmaları, bu uygulamada oldukça etkilidir. Özellikle, derin öğrenme algoritmaları, yüksek doğruluk oranlarına sahip olmaları nedeniyle tercih edilirler. Derin öğrenme algoritmaları, yapay sinir ağı mimarileri kullanarak verileri analiz eder ve karmaşık ilişkileri öğrenir. Bu sayede, göğüs kanseri sınıflandırılmasında elde edilen yüksek boyutlu ve karmaşık verileri işlemek daha kolay hale gelir.
Göğüs kanseri sınıflandırması, tıbbi uygulamaların bir örneğidir ve makine öğrenimi tekniklerinin sağlık sektöründe kullanılmasına örnek teşkil eder. Bu uygulama, kanser türlerinin erken teşhis edilmesine ve tedavi süreçlerinin optimize edilmesine yardımcı olur.

Göğüs Kanseri Veri Seti ve Sınıflandırması
Meme kanseri teşhisinde derin öğrenme yöntemlerinin kullanılması, doğru sonuçlar elde etmek için bir seçenek olabilir. Bu amaçla kullanılabilecek veri setlerinden biri, Wisconsin Üniversitesi Tıp Fakültesi’nde elde edilen Meme Kanseri Wisconsin (Teşhis) Veri Seti’dir. Bu veri seti, hücre görüntülerinden oluşmaktadır ve 569 örneği içermektedir. Her bir örnek, bir hücre örneğini temsil etmektedir.
Bu özellikler, hücre çekirdeği ile ilgili özellikler ve hücrenin genel özellikleri olarak sınıflandırılabilir. Hücreler, iyi huylu (benign) veya kötü huylu (malignant) olarak sınıflandırılmıştır. Bu veri seti, meme kanseri teşhisi için derin öğrenme algoritmaları ile kullanılabilecek bir örnek veri setidir. Bu veri seti üzerinde yapılacak çalışmalar, meme kanserinin doğru bir şekilde teşhis edilmesine yardımcı olabilir.
Derin öğrenme algoritmaları, bu veri seti üzerinde sınıflandırma problemini çözmek için kullanılabilir. Bu algoritmalar, özellikleri kullanarak hücreleri iyi huylu veya kötü huylu olarak sınıflandırabilirler. Veri seti, doğru bir şekilde işlenerek, eğitim ve test verileri olarak bölünebilir ve model eğitiminde kullanılabilir.
Sonuç olarak, Meme Kanseri Wisconsin (Teşhis) Veri Seti, meme kanseri teşhisi için kullanılabilecek bir veri setidir. Bu veri seti üzerinde derin öğrenme algoritmalarının kullanılması, meme kanserinin doğru bir şekilde teşhis edilmesine yardımcı olabilir.

Göğüs kanseri sınıflandırması, başarılı bir şekilde derin öğrenme yöntemleri kullanılarak gerçekleştirilebilmektedir. Bu amaçla, Meme Kanseri Wisconsin (Teşhis) Veri Seti gibi uygun veri setleri kullanılabilir. Bu veri seti, meme kanseri hücrelerinin görüntülerini ve bu hücrelerin 30 farklı özelliğini içermektedir. Bu özellikler, hücre çekirdeği ile ilgili özellikler ve hücrenin genel özellikleri şeklinde sınıflandırılabilir.
Veri setinde, hücrelerin iyi huylu veya kötü huylu olarak sınıflandırılmış halleri de yer almaktadır. Derin öğrenme algoritmaları, bu veri seti üzerinde eğitilerek, yeni örneklerin iyi huylu veya kötü huylu olarak sınıflandırılması mümkündür. Bu şekilde, göğüs kanseri teşhisi konusunda doğru sonuçlar elde edilebilir.
Derin öğrenme yöntemleri, birçok farklı model ve algoritma içermektedir. Bunlar arasında, yapay sinir ağları, evrişimli sinir ağları (CNN), tekrarlayan sinir ağları (RNN) ve derin öğrenme tabanlı sınıflandırma yöntemleri gibi teknikler yer almaktadır. Bu yöntemler, tıbbi uygulamalar gibi göğüs kanseri sınıflandırması gibi alandaki çalışmalarda da başarılı sonuçlar vermektedir.

Keşifsel – Açıklayıcı Veri Analizi
Keşifsel-Açıklayıcı Veri Analizi, veri kümesinin keşfedilmesi, anlaşılması ve görselleştirilmesi yoluyla veri analizinin gerçekleştirilmesidir. Bu yöntem, bir veri kümesindeki ilişkileri ve özellikleri anlamak için kullanılır.
Keşifsel veri analizi, verilerin özelliklerinin tanımlanması ve keşfedilmesine odaklanır. Bu aşamada, verilerin yapısı, dağılımı, eksik değerlerin varlığı, aykırı değerlerin olup olmadığı gibi özellikleri incelenir. Bu adımda amaç, veri kümesindeki trendleri ve özellikleri anlamak ve veri hikayesini oluşturmaktır. Bu aşama, veri setinin temel istatistiklerinin hesaplanması, grafiksel gösterimi ve veri setindeki özelliklerin belirlenmesi gibi işlemleri içerir.
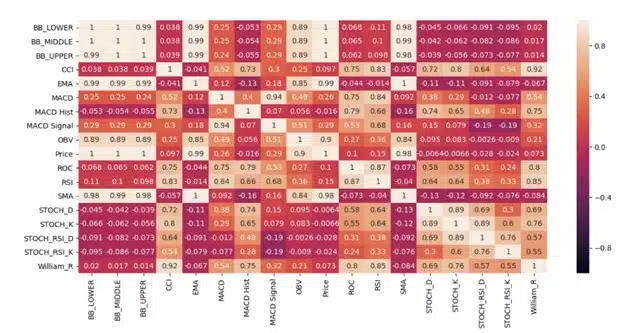
Açıklayıcı veri analizi ise, veri setinin daha ayrıntılı bir şekilde incelenmesini ve spesifik bir soruya cevap bulmayı hedefler. Bu aşamada, veri kümesindeki özellikler arasındaki ilişkiler ve etkiler analiz edilir. Bu adımda amaç, elde edilen sonuçları yorumlamak ve açıklamaktadır. Bu aşama, veri setindeki değişkenler arasındaki korelasyon analizi, regresyon analizi ve hipotez testleri gibi istatistiksel yöntemleri içerir.
Keşifsel-Açıklayıcı Veri Analizi, veri tabanlı karar verme ve problem çözme sürecinin önemli bir adımıdır. Bu yöntem, verilerin anlaşılması ve yorumlanması yoluyla, problem alanı hakkında daha fazla bilgi edinilmesine ve daha doğru kararlar vermesine yardımcı olur.

Outlier Detection – Local Outlier Factor Yöntemi
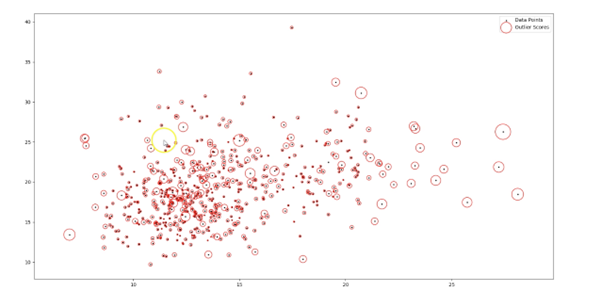
Outlier Detection (Aykırı Veri Tespiti), veri setinde beklenmeyen veya anormal değerleri tespit etmek için kullanılan bir yöntemdir. Local Outlier Factor (LOF) yöntemi, aykırı değerleri tespit etmek için sıklıkla kullanılan bir yöntemdir.
LOF yöntemi, bir veri noktasının yerel yoğunluğunun diğer veri noktalarının yoğunluğu ile karşılaştırılmasına dayanır. Bir veri noktasının yoğunluğu, belirli bir yarıçap içindeki diğer veri noktalarının sayısı ile ölçülür. Eğer bir veri noktası, diğerlerine göre daha seyrek bir bölgede yer alıyorsa, bu durumda LOF değeri yüksek olacaktır ve bu veri noktası bir aykırı olarak tanımlanabilir.
LOF yöntemi, aynı zamanda bir veri noktasının yoğunluğunu etkileyen komşuluk boyutu faktörünü de dikkate alır. Bu faktör, veri setindeki veri noktalarının birbirlerine olan uzaklıklarına göre belirlenir. Komşuluk boyutu faktörü arttıkça, daha geniş bir yarıçap içindeki veri noktaları da hesaba katılır ve bu da daha az aykırı veri noktası tespit edilmesine neden olur.
LOF yöntemi, büyük veri setleri üzerinde etkili bir şekilde çalışabilir ve diğer yöntemlerden daha az hesaplama maliyeti gerektirir. Ayrıca, LOF yöntemi, veri setindeki aykırı değerlerin çıkarılmasının yanı sıra, veri setindeki farklı gruplar veya kümeleme yapılarının da tespit edilmesine yardımcı olabilir.
Outlier’ların Tespiti ve Çıkarılması
Outlier, bir veri kümesindeki diğer verilere göre anormal derecede farklı olan bir veya birkaç veri noktasıdır. Bu farklılık, verilerin yanlışlıkla veya kasıtlı olarak girilmesi veya gerçek hayatta nadir görülen olaylar nedeniyle oluşabilir. Outlier’ların tespiti ve çıkarılması, doğru sonuçlar elde etmek için veri analizinde önemli bir adımdır.
Outlier’ların tespiti ve çıkarılması için çeşitli yöntemler vardır. İstatistiksel yöntemler, veri kümesinin dağılımı ve temel istatistiksel özellikleri kullanarak outlier’ları tespit eder. Grafiksel yöntemler, verilerin grafikler üzerinde gösterilmesi yoluyla outlier’ları tespit eder. Makine öğrenimi yöntemleri ise, verilerin özelliklerine dayalı olarak outlier’ları tespit eder.
En yaygın kullanılan yöntemler arasında Local Outlier Factor (LOF), Isolation Forest, K-Nearest Neighbors (KNN), One-Class SVM (Support Vector Machine) ve DBSCAN (Density-Based Spatial Clustering of Applications with Noise) gibi makine öğrenimi yöntemleri bulunmaktadır. Bu yöntemler, veri kümesindeki özellikleri analiz ederek outlier’ları tespit ederler.
Outlier’ların tespiti ve çıkarılması, veri analizi ve makine öğrenimi gibi alanlarda önemlidir. Bu yöntemler, veri kümesindeki hatalı veya yanıltıcı verilerin tespit edilmesine ve çıkarılmasına yardımcı olur. Bu sayede, daha doğru sonuçlar elde edilir ve doğru kararlar verilir.

Standardization
Standardizasyon (standartlaştırma), veri ön işleme sürecinde sıklıkla kullanılan bir yöntemdir. Veri kümesindeki sayısal özelliklerin, belirli bir ölçekte ve özellik dağılımı ile ifade edilmesini sağlar.
Göğüs kanseri derin öğrenme çalışmalarında da veri standardizasyonu kullanılabilir. Örneğin, meme kanseri görüntülerinin piksel değerleri kullanılarak bir derin öğrenme modeli eğitilecekse, piksel değerlerinin farklı ölçeklerde veya dağılımlarda olması modelin performansını olumsuz etkileyebilir.
Bu nedenle, verilerin özelliklerinin standartlaştırılması, verilerin benzer bir ölçeğe ve dağılıma sahip olmasını sağlar. Standartlaştırma yöntemleri arasında en yaygın olanı, özellik ölçeğini sıfır ortalamalı ve birim varyanslı bir normal dağılıma dönüştürmektir. Bu yöntem, Z-score normalleştirme veya standart sapma yöntemi olarak da bilinir.
Örneğin, meme kanseri görüntü veri kümesindeki piksel değerleri Z-score normalleştirme yöntemi ile standart ulaştırılabilir. Bu sayede, her bir özelliğin benzer bir ölçeğe sahip olduğu ve dağılımlarının benzer olduğu bir veri kümesi elde edilir. Bu veri kümesi, daha sonra derin öğrenme modelinde kullanılabilir ve modelin performansı arttırılabilir.

K-Nearest Neighbors(KNN) Nedir?
K-Nearest Neighbors (KNN), bir sınıflandırma veya regresyon algoritmasıdır. Bu algoritma, öğrenme aşamasında veri noktalarının birbirine olan benzerliklerine dayalı olarak örüntüleri tanımlar. KNN algoritması, bir veri noktasının sınıflandırmasını belirlemek için komşu veri noktalarının sınıflarını kullanır. Bu nedenle, KNN, temel olarak örüntü tanıma ve sınıflandırma problemleri için kullanılır.
KNN, bir örnek tabanlı öğrenme yöntemidir. Yani, öğrenme aşamasında, veri setindeki her bir örnek, bir sınıfa atanmış bir etiketle birlikte depolanır. KNN algoritması, sınıflandırma yaparken, verilen bir test örneğini alır ve test örneği ile en yakın komşularını (K komşu) bulmak için bir mesafe ölçütü kullanır. Bu K komşuya göre, test örneği, sınıflandırması için çoğunluk oyu kullanılarak sınıflandırılır.
KNN algoritmasında en önemli parametre K, belirlenmesi gereken bir parametredir. K, komşu sayısını belirler ve genellikle tek sayı olarak seçilir, böylece oylama sonucu bir sınıfa düşer. K’nın artması, modelin karmaşıklığını arttırır ve aşırı uyma riskini azaltırken, K’nın azaltılması modelin esnekliğini arttırır ancak aşırı uyma riskini arttırır.
KNN algoritması, özellikle küçük veri kümeleri için etkilidir, ancak veri kümesi büyüdükçe hesaplama maliyeti artar. KNN algoritması ayrıca, özniteliklerin ölçeği ve mesafe ölçütünün seçimi gibi bazı önemli sorunlarla karşı karşıya kalabilir ve bu sorunlar, modelin performansını etkileyebilir.
Principal Component Analysis(PCA) Nedir?
Principal Component Analysis (PCA), bir veri kümesinin boyutunu azaltmak için kullanılan bir makine öğrenimi tekniğidir. Veri kümesindeki değişken sayısını azaltır ve veri setindeki temel özelliklerin ortaya çıkarılmasına yardımcı olur.
PCA, çok boyutlu veri setlerindeki yapısal ilişkileri ve değişkenler arasındaki korelasyonları analiz eder. Bu analiz sonucunda, orijinal veri kümesindeki değişkenlerin en önemli olanları seçilir ve yeni bir veri kümesi oluşturulur. Yeni veri kümesi, orijinal veri kümesinden daha az boyutlu olmakla birlikte, veri setinin temel özelliklerini korur.
PCA, bir veri kümesindeki en büyük varyansı yakalamak için kullanılır. Yeni veri kümesindeki değişkenler, orijinal veri kümesindeki değişkenlerin birleşimi şeklinde oluşur ve yeni değişkenler, birincil bileşenler olarak adlandırılır.
PCA’nın uygulanması için öncelikle veri kümesindeki değişkenlerin standardize edilmesi gereklidir. Daha sonra, kovaryans matrisi hesaplanır ve bu matrisin özvektörleri ve özdeğerleri bulunur. Özvektörler, orijinal veri kümesindeki değişkenlerin lineer kombinasyonlarını temsil eder. Özdeğerler ise, orijinal veri kümesindeki değişkenlerin varyansını gösterir.
PCA, birçok farklı alanda kullanılır, örneğin finansal analiz, görüntü işleme, veri sıkıştırma ve biyolojik verilerin analizi gibi. PCA, büyük boyutlu veri setlerinde kullanıldığında, boyut düşürme sayesinde veri işleme süresini azaltabilir ve hesaplama maliyetlerini düşürebilir.