Yapay zekâ alanında yaşanan hızlı gelişmeler, büyük dil modeli gibi çeşitli alanlarda yeni iş modelleri geliştirilmesinin önünü açmıştır. Yapay Zeka kronolojisine baktığımızda aslında “Transformer” teknolojisi ile büyük bir başlangıca ilk adımı insanlık olarak attığımızı söyleyebiliriz. Peki nedir Transformerlar kısaca hatırlayalım:
Transformer, özellikle doğal dil işleme (NLP) ve yapay zekâ (AI) alanlarında büyük bir etki yaratmış olan bir derin öğrenme modelidir. Bu model, Google tarafından 2017 yılında “Attention Is All You Need” [1] başlıklı bir makalede tanıtılmıştır. Transformer modeli, özellikle büyük veri kümesi üzerinde eğitilmiş ve sonuç olarak çeviri, dil modellenmesi, metin sınıflandırma ve daha birçok görevde büyük başarı elde etmiştir. Bu mimari Kodlayıcı ve Çözücü olmak üzere iki bileşenden oluşan Seq2Seq bir mimaridir. Modelin mimari çizimini Şekil 1’de görebilirsiniz:

Peki Nedir Transformar’ın teknik özellikleri:
- Öz-dikkat ve Dikkat Mekanızmaları: Modelin en temel yeniliğini oluşturan dikkat mekanizması metin girdisi ile birlikte hangi elemanın daha öncelikli olduğunu belirten bir attention dizisine sahip olmasıdır. Böylece model girdi metninin önemli kısımlarına odaklanabilrmektedir. Bağlamsal anlamları güçlendirmeyi sağlar. Öz-dikkat mekanizması ise bir elemanın diğer elemanlarla olan ilişkisini modellemeyi sağlar.
- Pozisyonel Kodlama ve Paralel İşlem: Transformer bir kelimenin gönderilen girdinin kaçıncı elemanı olduğunu da kodlar. Pozisyonel kodlama RNN, LSTM gibi geleneksel derin öğrenme yöntemlerinden farklı olarak paralel işlem yapabilmeyi sağlar. Bu, eğitim ve çeviri gibi görevlerin daha hızlı tamamlanmasını sağlamaktadır.
- Çoklu Başlık Dikkat (Multi-Head Attention): Transformer modeli, dikkat mekanizmasını birden fazla başlık (head) kullanarak uygular. Her başlık, farklı özelliklere dikkat eder ve daha sonra sonuçları birleştirir. Bu, modelin farklı dil özelliklerini yakalamasına yardımcı olur.
Transformer’ın önerilmesinin hemen arkasından Büyük Dil Modeli kavramı teknik olarak hayatımıza girdi. Şekil1’ de bir transformera ait iki alt modülü görüyoruz. Sol taraf Kodlayıcı ve sağ taraf Çözücü olarak nitelendirilmektedir.
BERT (Bidirectional Encoder Representations from Transformers)
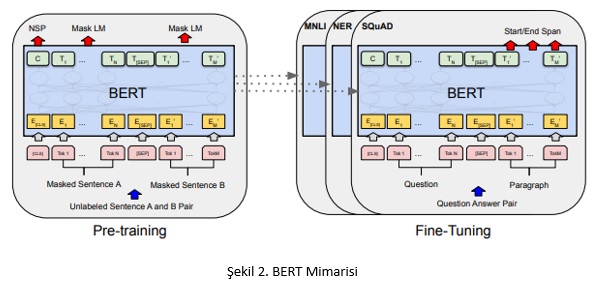
Önceden eğitilmiş bir dil modeli olan BERT [2] Kodlayıcıların ard arda bağlanmasıyla elde edilen Google tarafından önerilmiş bir modeldir. Model, 3.3 milyar kelime içeren Wikipedia ve 2.5 milyar kelime içeren BookCorpus adlı iki büyük veri kümesinde eğitilmiştir. Önceden eğitilmiş kavramı şu anlama gelmektedir: Elimizde büyük bir veri ile eğitilmiş bir dil modelleyicimiz var ve biz istediğimiz bir özel görev için ona ince-ayar yapabiliriz. Şekil 2’de BERT modelini ve ince-ayarlanmasını görebilirsiniz. E1, E2, …, Em art arda bağlanmış Kodlayıcıları temsil etmektedir. BERT, maskeli dil modelleme (MLM) ve sonraki cümle tahmini (NSP) hedefleriyle eğitilmiş bu sebeple birazdan bahsedeceğimiz Büyük Dil Modelleri (Large Language Model – LLM) gibi üretici değildir. Bunun yerine sınıflandırma, soru cevaplama ve varlık tanıma (Named Entity Recognition – NER) problemlerini çözmek için sıklıkla kullanılmaktadır.

GPT (Generative Pre-trained Transformer)
OpenAI tarafından önerilen GPT modeli transformer modelinin Çözücü bloklarının art arda bağlanması ile elde edilmiştir. Bu model daha çok çeviri, üretme gibi görevlerde kullanılmaktadır. Üretici modeller metin işleme konusunda çok sayıda probleme çözüm üretmektedir. Örneğin elinizdeki üretici modelinize bir şiir veya bir hikâye yazdırabilirsiniz. Veya kendi verileriniz için https://www.chatbase.co/#demo üzerinden ChatGPT chatbot oluşturabilirsiniz. GPT’ ye birlikte bir şiir yazdıralım:

OpenAI GPT-2 [3] gibi bazı modelleri ücretsiz erişime açmaktadır. GPT-2, büyük bir dikkat mekanizması kullanarak öğrenir. Bu dikkat mekanizması, modelin önceki kelime ve cümleleri anlamasına ve ardından bir sonraki kelimeyi öngörmesine olanak tanır. Model, milyonlarca parametre içeren bir derin öğrenme ağıdır ve doğal dil işleme alanında önemli bir ilerlemedir.
GTP3.5 ve GPT4 gibi daha büyük mimariye sahip gelişmiş modeller ise ücret karşılığında SaaS olarak OpenAI tarafından sunmaktadır. GPT türü modellerde büyüklük mimaride kullanılan Çözücü sayısı ile doğru orantılıdır.
Llma
Meta tarafından geliştirilmiş bu büyük dil modelinin en önemli özelliği MIT lisansı ile açık kaynak kodlu olarak bireysel ve ticari kullanıma açılmasıdır. Llama2 Llama1’e göre %40 daha fazla kaynakla beslenmiştir, 2 katı daha fazla bağlam uzunluğuna sahiptir. Llma 2 modeli 18 Temmuz 2023’ te kullanıma sunulmuştur. Bu modeli farklı kılan bir diğer özellik güvenlilik odaklı verilerle eğitilmesidir. Bu model eğitilirken 1 milyon’a yakın insan geribildirimi verisi pekiştirmeli Öğrenme sürecine dahil edilmiştir. Kendine özgü hayalet (ghost) dikkat mekanizması kullanmıştır. İnsan değerlendirmesine göre GPT 3’ten daha iyi sonuçlar elde etmiştir fakat en büyük kısıtı neredeyse tamamen İngilizce dili için eğitilmiş olmasıdır. Bu modelin Türkçe desteği bulunmamaktadır. Modelden teknik bir konuya açıklama oluşturmasını istedim:

Falcon
Abu Dabi’deki Teknoloji İnovasyon Enstitüsü (TII) tarafından geliştirilen yeni bir Açık Kaynak Büyük Dil Modeli ise Falcon’dur. Falcon [4], Apache 2.0 lisansı altında piyasaya sürülen ilk “gerçekten açık” modeldir. Falcon, GPT-3’ten (Brown ve diğerleri, 2020) uyarlanmış, yalnızca kod çözücü içeren bir modeldir ancak konumsal yerleştirmeler, dikkat (multiquery ve FlashAttention) ve kod çözücü bloğu konusunda bazı mimari farklılıklara sahiptir. Falcon ailesinde Falcon-40B ve daha küçük olan Falcon-7B olmak üzere iki temel model bulunur. Modelin performans sonuçları LLM Leaderboard da diğer açık kaynak kodlu modeller arasında en yüksek olarak paylaşılmıştır.

Bu yazımızda büyük dil modeli kavramına bir giriş yaptık. Ayrıca yazı içerisinde en büyük dört oyuncunun modelleri ile ilgili bilgiler verdik. Bir diğer yazımızda büyük dil modellerinin alana özel problemlerde nasıl kullanılabileceğinden örneklerle bahsedeceğiz.
Referanslar
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[2] Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
[3] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). Language models are unsupervised multitask learners. OpenAI blog, 1(8), 9.
[4] Almazrouei, E., Alobeidli, H., Alshamsi, A., Cappelli, A., Cojocaru, R., Debbah, M., … & Penedo, G. (2023). Falcon-40B: an open large language model with state-of-the-art performance.