PANAS-TPANAS (Positive and Negative Affect Schedule) Türkçe ismiyle Pozitif ve Negatif Duygu Durum ölçeği,bireylerin duygu durum eğilimlerinin ve bozukluklarının ölçülmesi için Watson ve Tellegen tarafındangeliştirilmiş bir psikometrik ölçektir. Toplam 20 sorudan oluşan bir anket şeklindeuygulanır ve temelde bir öz bildirim anketidir. Analiz öznesine 10’u negatif, 10’u da pozitif duygu durumunu ifade eden kelimelerden oluşan sorular yöneltilir ve alınan cevaplar neticesinde analiz edilen kişinin duygu durumuna ilişkinyargılaraulaşılır.
Testin geçerlilik ve güvenilirlik testleri yapılmış buna ek olarak duygu durumlarını ifade eden kelimeler için faktör yükleri ayrıayrıhesaplanmıştır. Bu hesaplamalar farklı diller için yapıldığı gibi Türkçe dili içinde yapılmıştır ve PANAS Türkçe dilinde klinik psikologlar ve psikiyatristler tarafındanaktif olarak kullanılmaktadır.PANAS’ın Türkçe çevirisi ve faktör yükü hesaplamaları 1998 yılında Dürü tarafından yapılmıştır
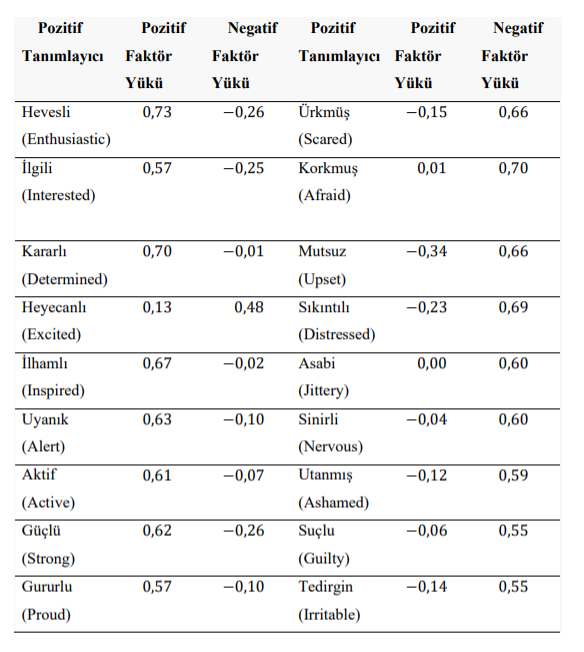
Faktör yüklerindeki ana fikir bir duygu durumunu yoğun olarak ifade eden betimleyici sıfatın, karşıt duygu durumunda olabildiğince nötr bir değer almasıdır. Böylece ankette cevap verilen betimleyici sıfatların tümü kendi duygu durumunda izole bir biçimde hesaplanabilir.
PANAS’ın birden çok versiyonu yapılmıştır. Çocuklar için PANAS-C ve daha farklı duygu gruplarının ölçümünde kullanılan genişletilmiş PANAS-X gibi. Bilgisayar uygulamaları içinse PANAS ölçekleri adapte edilmeye başlanmıştır. Bunlardan en bilineni Gonçalves, Benevenuto ve Cha’nın geliştirdiği PANAS-t (A Psychometric Scale for Measuring Sentiments on Twitter)’dır . Bu çalışmada PANAS’ın genişletilmiş versiyonu olan PANAS-X ’in betimleyici sıfatları kullanılarak, anahtar kelimelere dönüştürülmüştür. Bilinen en geniş kapsamlı çalışma olan bu çalışmada yaklaşık 1.8 milyar Tweet analiz edilmiş ve normalizasyon değerleri bu veri kümesi üzerinden elde edilmiştir.
Datakapital ise 2022 yılında PANAS’ın orijinal versiyonunu kullanarak benzer bir çalışma yapmıştır ve seçilen belli gündemler hakkında PANAS ölçeği kullanılarak yapılan anketlerle benzer sonuçlara PANAS-T’yi kullanarak Twitter içerikleri üzerinden ulaşmaya çalışmıştır. Türkçe dili için yapılan bu çalışmada yaklaşık 328 milyon Twitter içeriği kullanılmıştır.
Çalışma neticesinde sentiment modülü ile desteklenmeyen bir PANAS-T Türkçe uygulamasının, anket verileriyle 0.20 düzeyinin altında korelasyona sahip olduğu ve istenen güçlü ilişkiyi sağlamadığı tespit edilmiştir. İngilizce dili ile yapılan çalışmalar anket verileriyle desteklenmediği için mukayese edilebilecek bir korelasyon bilgisi yoktur. Mukayese imkanı olsa dahi 0.20 seviyesindeki bir korelasyonun psikometrik ölçeği karşılamadığı aşikardır.
Çalışma süresince bu düşük korelasyon seviyesinin nedenleri araştırılmış ve Türkçe dilindeki Twitter içeriklerinde bir duygu grubundaki betimleyici sıfatın, karşıt duygu grubunda anlam yüklendiği tespit edilmiştir. Normalde PANAS anket olarak deneğe verildiği için, betimleyici sıfatlar istenen bağlamda kullanılarak deneğe sorulmaktadır ancak Twitter’da betimleyici sıfatın içinde bulunduğu içerik PANAS’a göre yapılandırılmamış olarak elde edilmektedir. Bu sorunun çözümü için Datakapital geliştirdiği sentiment modülleriyle içerikleri filtrelemiş ve betimleyici sıfatların karşıt duygu grubunda anlam yüklendiği içerikler analize alınmamıştır.
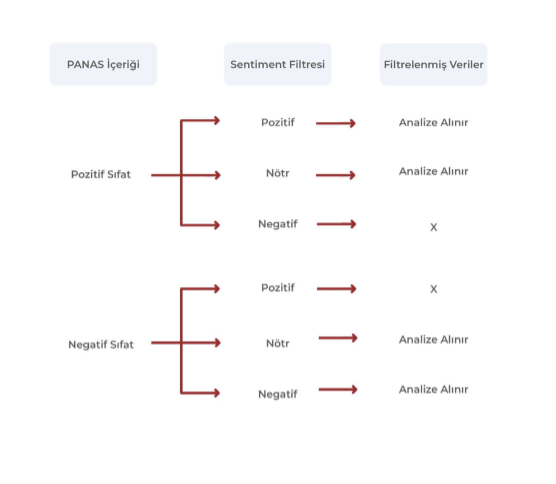
Yapılan filtreleme neticesinde 0,70 ve üzeri korelasyon katsayılarına ulaşılmıştır. Bu çalışmayı baz alarak Datakapital PANAS modüllerini gündem analizlerine entegre etmeye çalışmaktadır.