Konvolüsyonel Sinir Ağları (Convolutional Neural Networks veya CNNs), resim, video, metin ve ses gibi girdi verileri üzerinde derin öğrenme algoritmaları olarak kullanılan bir yapılandırılmış öğrenme yöntemidir.
Bu ağlar, nesne tanıma, yüz tanıma, görüntü sınıflandırma, nesne tespiti, dil işleme gibi birçok uygulamada kullanılır. CNN’ler, girdi verilerindeki özellikleri tanımlamak için tasarlanmış özel bir sinir ağıdır.
CNN’ler, normal sinir ağlarından farklı olarak, filtreler veya çekirdekler adı verilen küçük matrisler kullanarak girdi verilerindeki özellikleri belirler. Bu filtreler, girdi verilerinde kaydırılır ve her konumda bir çıktı üretir. Bu sayede, ağ girdi verilerindeki özellikleri öğrenir ve daha sonra bu özellikleri daha yüksek seviyeli özelliklere birleştirir.

CNN’ler, katmanlar arasında paylaşılan parametrelerle birleştirilerek öğrenme sürecini hızlandırır ve aynı zamanda ağın genelleştirme yeteneğini artırır. Bu nedenle, özellikle görüntü işlemede, birçok görevde yüksek doğruluk ve performans sağlayan en iyi derin öğrenme yöntemlerinden biri olarak kabul edilir.

CNN ile MNIST Nedir?
MNIST, el yazısı rakamlarının görüntülerinden oluşan bir veri kümesidir ve makine öğrenmesi alanında yaygın bir sınıflandırma problemi olarak kullanılır. CNN’ler, MNIST gibi resim sınıflandırma problemleri için özellikle uygun bir derin öğrenme yöntemidir.
MNIST veri kümesinde, her biri 28×28 piksel boyutunda 60.000 eğitim örneği ve 10.000 test örneği bulunmaktadır. CNN’ler, girdi verilerindeki özellikleri belirlemek için filtreler veya çekirdekler adı verilen küçük matrisler kullanır. Bu filtreler, girdi verilerinde kaydırılır ve her konumda bir çıktı oluşturur. Bu sayede, ağ, girdi verilerindeki özellikleri öğrenir ve daha sonra bu özellikleri daha yüksek seviyeli özelliklere birleştirir.

MNIST veri kümesinde, her bir rakamın sınıflandırılması için 10 farklı sınıf vardır. CNN’ler, bu sınıflandırma görevini gerçekleştirmek için, ardışık katmanlarında filtreler kullanarak, girdi verilerindeki özellikleri belirler ve bu özellikleri daha yüksek seviyeli özelliklere birleştirir. Son katman, sınıflandırma işlemi için bir çıktı üretir.
CNN’ler, MNIST veri kümesindeki rakamları sınıflandırmak için kullanılan en etkili yöntemlerden biridir. Öğrenme süreci, katmanlar arasında paylaşılan parametrelerin birleştirilmesi sayesinde hızlandırılır ve aynı zamanda ağın genelleştirme yeteneği artırılır. Sonuç olarak, CNN’ler, MNIST gibi resim sınıflandırma problemlerinde yüksek doğruluk ve performans sağlayan bir derin öğrenme yöntemidir.
CNN ile MNIST Karşılaştırılması
- MNIST veri kümesi geleneksel özellik çıkarma yöntemleri kullanıldığında bile yüksek doğruluk oranlarına sahiptir.
- Geleneksel yöntemler, özellik çıkarma yöntemleri kullanır ve bu özellikler daha sonra sınıflandırma işlemi için bir öğrenme algoritması tarafından işlenir.
- CNN’ler, özellik çıkarma işlevlerini kendiliğinden öğrenir ve bu sayede daha yüksek doğruluk oranları elde edilebilir.
- CNN’ler, MNIST veri kümesinde yüksek doğruluk oranları elde etmek için oldukça etkili bir yöntemdir.
- CNN’lerin kullanımı, özellik çıkarma işlevlerinin kendiliğinden öğrenilmesi ve öğrenme sürecinin hızlandırılması nedeniyle, MNIST gibi resim sınıflandırma problemlerinde geleneksel yöntemlere göre daha iyi sonuçlar verir.
- MNIST veri kümesi, CNN’lerin performansının değerlendirilmesi için sık sık kullanılan bir test platformu haline gelmiştir.
El yazısı rakamlarını sınıflandırmak için bir CNN kullanarak MNIST veri kümesini eğitmek için örnek bir Python kodu aşağıda verilmiştir;
import tensorflow as tf
from tensorflow.keras.datasets import mnist
# Veri kümesini yükle
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# Veri kümesini normalize et
x_train = x_train / 255.0
x_test = x_test / 255.0
# Modeli oluştur
model = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Conv2D(64, (3, 3), activation=’relu’),
tf.keras.layers.MaxPooling2D((2, 2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation=’softmax’)
])
# Modeli derle
model.compile(optimizer=’adam’,
loss=’sparse_categorical_crossentropy’,
metrics=[‘accuracy’])
# Modeli eğit
model.fit(x_train.reshape(-1, 28, 28, 1), y_train, epochs=5, validation_data=(x_test.reshape(-1, 28, 28, 1), y_test))
Bu kod, TensorFlow kütüphanesi kullanılarak bir CNN modeli oluşturur ve MNIST veri kümesindeki el yazısı rakamları sınıflandırmak için eğitir. Modelde iki katmanlı bir konvolüsyon katmanı, iki katmanlı bir max pooling katmanı ve bir tam bağlantılı katman kullanılır. Eğitim, 5 epoch boyunca yapılır ve her epoch sonunda modelin doğruluğu ekrana yazdırılır.
CIFAR -10 Nedir?
CIFAR-10, derin öğrenme modellerinin performansının değerlendirilmesi için yaygın olarak kullanılan bir görüntü sınıflandırma veri kümesidir. Veri kümesi, 10 farklı nesne sınıfını içerir ve her sınıf 6,000 görüntüden oluşur. Görüntüler, 32×32 piksel boyutlarında renkli görüntülerdir ve sınıflandırma problemi, arka plan gibi detayları da içeren daha karmaşık ve zorlu bir görev sunar.
CIFAR-10, MNIST veri kümesine kıyasla daha büyük ve karmaşık veriler içerir ve bu nedenle daha zor bir sınıflandırma problemi sunar. Bu veri kümesi, derin öğrenme araştırmacılarının yeni yöntemlerini ve model yapılarını test etmek için sık sık kullanılan bir platformdur. CIFAR-10 veri kümesi üzerinde yapılan sanal yarışmalar ve sınıflandırma yarışmaları da bu veri kümesinin önemini artırmaktadır.

CIFAR-10 veri kümesi, aynı zamanda bilgisayar görüşü araştırmalarında sık kullanılan bir örnektir ve özellikle konvolüsyonel sinir ağları gibi derin öğrenme modelleri üzerinde çalışan araştırmacılar tarafından sık sık kullanılmaktadır. Bu veri kümesi, farklı derin öğrenme modelleri arasında karşılaştırmalar yapmak ve performanslarını değerlendirmek için de sıklıkla kullanılmaktadır.
CIFAR-10 veri kümesi üzerinde bir model oluşturmak için PyTorch kütüphanesi kullanarak bir örnek kod aşağıdaki gibidir;
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
# CIFAR-10 verilerini yükleme ve ön işleme
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root=’./data’, train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root=’./data’, train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
# CIFAR-10 sınıf isimleri
classes = (‘uçak’, ‘otomobil’, ‘kuş’, ‘kedi’,
‘gazal’, ‘köpek’, ‘kurbağa’, ‘at’, ‘gemi’, ‘kamyon’)
# CNN modeli oluşturma
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
# Cross-entropy loss fonksiyonu ve SGD optimizer kullanarak modeli eğitme
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # 2 epoch için eğitim yapılacak
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 2000 == 1999: # her 2000 batch’de bir kayıp yazdır
print(‘[%d, %5d] loss: %.3f’ %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print(‘Eğitim tamamlandı’)
# Test verileri üzerinde modelin performansını test etme
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
Overfitting Problemi Nedir
Overfitting, bir makine öğrenimi modelinin eğitim verilerine aşırı uyum sağladığı ve bu nedenle yeni veriler üzerinde düşük performans gösterdiği bir durumdur. Bu durumda model, eğitim verilerindeki rastgele veya gürültülü verileri de dahil olmak üzere her bir örneği ezberlemeye eğilimlidir.
Overfitting’i önlemek için birkaç yöntem vardır. Bunlar;
Daha fazla veri toplama
Overfitting, genellikle az sayıda eğitim verisi olduğunda ortaya çıkar. Daha fazla veri toplamak, modelin genelleyebileceği daha fazla örnek sağlayabilir.
Model karmaşıklığını azaltma
Daha basit modeller, genellikle daha az overfitting’e eğilimli olabilirler. Bu nedenle, modelin karmaşıklığını azaltmak, overfitting’i önlemek için önemli bir yöntemdir.
Düzenlileştirme teknikleri kullanma
Düzenlileştirme, overfitting’i önlemek için kullanılan bir tekniktir. L1 ve L2 düzenlileştirme, dropout ve maksimum norm kısıtlamaları gibi teknikler, modelin aşırı uyumunu azaltmak için kullanılabilir.
Dropout kullanma
Dropout, ağın her bir katmanında rastgele olarak seçilen bir dizi nöronu devre dışı bırakarak çalışır. Bu, her bir öğrenme döngüsünde farklı bir alt kümeyle çalıştığından, modelin overfitting’e eğilimini azaltabilir.
Erken durdurma
Erken durdurma, modelin overfitting yapmasını önlemek için kullanılan bir başka tekniktir. Bu teknik, modelin eğitim verilerindeki performansı belirli bir eşik değere ulaştığında eğitimi durdurur.

Örnek bir Python kodu ile overfitting örneği aşağıdaki gibi olabilir;
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
# MNIST veri kümesini yükleme
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# Veri önişleme
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype(‘float32’) / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype(‘float32’) / 255
# Etiketleri kategorik hale getirme
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# Ağ modelini tanımlama
model = Sequential()
model.add(Dense(512, activation=’relu’, input_shape=(28 * 28,)))
model.add(Dense(10, activation=’softmax’))
# Modeli derleme
model.compile(optimizer=’rmsprop’, loss=’categorical_crossentropy’, metrics=[‘accuracy’])
# Modeli eğitme
history
Data Augmentation Nedir?
Data augmentation, makine öğrenimi ve derin öğrenme modellerinde kullanılan bir tekniktir. Veri artırma olarak da bilinir ve eğitim verilerinin çeşitliliğini artırırken, modelin genel performansını iyileştirmeyi amaçlar.
Data augmentation, özellikle sınırlı miktarda veriye sahip olduğumuz durumlarda çok faydalıdır. Örneğin, bir nesne algılama modeli için, sadece sınırlı sayıda nesne görüntüsüne sahip olabiliriz. Bu durumda, modelin daha iyi genelleştirme yapabilmesi için, eğitim verilerini çeşitlendirmek gerekebilir.
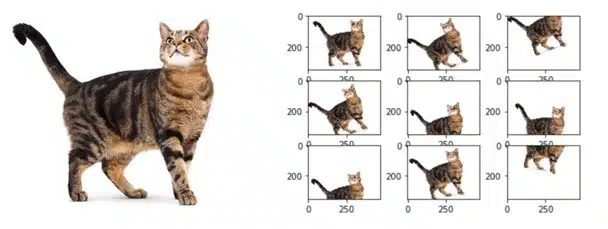
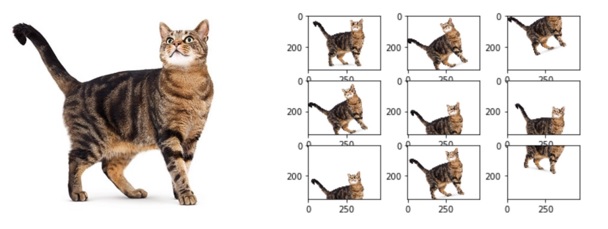
Data augmentation, mevcut verileri değiştirerek yeni veriler oluşturur. Bu işlem, görüntülerdeki dönüşüm, kaydırma, zoomlama, parlaklık değişimi ve renk değişimi gibi çeşitli teknikler kullanılarak gerçekleştirilir. Bu teknikler, verilerin çeşitliliğini artırır ve modelin gerçek dünya verilerine daha iyi uyum sağlamasına yardımcı olur.
Örneğin, bir resim sınıflandırma modeli için, aynalama (flip), döndürme (rotation), kesme (crop) gibi teknikler kullanılabilir. Bu teknikler sayesinde, model, nesnelerin farklı açılardan, farklı boyutlarda ve farklı konumlarda göründüğü çeşitli resimlere maruz kalır. Bu da modelin daha genel bir resim anlayışı geliştirmesine yardımcı olur.
Data augmentation, derin öğrenme modellerinin genel performansını artırmak için sıkça kullanılan bir teknik olmasına rağmen, aşırı öğrenme problemini çözmek için tek başına yeterli değildir. Bu nedenle, data augmentation teknikleri, düzenlileştirme teknikleri gibi diğer tekniklerle birlikte kullanılmalıdır.
Batch Normalization Nedir?
Batch Normalization, bir derin öğrenme modelindeki her bir katmandan çıkan aktivasyonların dağılımını normalleştirerek, eğitim sürecinde daha hızlı ve daha istikrarlı bir şekilde konverjan sağlamak amacıyla kullanılan bir yöntemdir.
Daha spesifik olarak, Batch Normalization, mini-batch verilerinin ortalamasını ve varyansını hesaplar ve ardından bu değerleri kullanarak aktivasyonları ortalaması 0 ve varyansı 1 olan bir normal dağılım şeklinde yeniden ölçeklendir. Bu işlem, verilerdeki kayıp gradientlerin dağılımını düzenleyerek, daha verimli bir öğrenme süreci sağlar.
Batch Normalization, ayrıca aşırı uydurma (overfitting) problemlerini de azaltabilir. Çünkü, aşırı uydurma problemleri, aktivasyonların dağılımındaki değişkenlik nedeniyle oluşabilir. Batch Normalization, aktivasyonların dağılımını dengelerken, aşırı uydurma problemlerinin önlenmesine yardımcı olur.
Batch Normalization, birçok derin öğrenme modelinde yaygın olarak kullanılan bir yöntemdir ve ağırlıklı olarak konvolüsyonel sinir ağları (CNN’ler) ve tam bağlantılı yapılarda kullanılır.
Örnek bir Batch Normalization uygulaması;
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation=’relu’, input_shape=(28,28,1)))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation=’relu’))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation=’relu’))
model.add(BatchNormalization())
model.add(Dense(10, activation=’softmax’))
Konvolüsyonel Sinir Ağları Modelleri Kaydetme
Bir makine öğrenimi modelinin eğitimi, veriler üzerindeki optimize edilmiş parametrelerin bir setini içerir. Bu parametreler, modelin verileri nasıl yorumladığı ve gelecekteki tahminleri nasıl yapacağı hakkında bilgi sağlar. Eğitim süreci, bir modelin belirli bir veri kümesi için öğrenmesini sağlar, ancak modelin sonuçlarını kullanmak için genellikle eğitim verileri dışındaki yeni verileri kullanmak gerekmektedir.
Bu nedenle, bir modelin eğitilmesi ve sonuçlarının kaydedilmesi önemlidir. Modelin kaydedilmesi, modelin gelecekteki kullanımlar için kullanılabilir olmasını sağlar. Ayrıca, eğitim sürecinde zaman ve çaba harcanan parametrelerin yeniden kullanılmasına da olanak tanır.
Modellerin kaydedilmesi, birçok farklı formatta yapılabilir. Bazı yaygın formatlar arasında TensorFlow SavedModel, Keras modeli, PyTorch modeli, ONNX modeli ve daha birçok format bulunmaktadır. Kaydetme süreci, bir modelin ağırlıklarının ve yapısının uygun bir şekilde saklanmasını içerir.
Bir modelin kaydedilmesi, aynı zamanda modelin belirli bir noktada eğitimini durdurmanız gerektiğinde de önemlidir. Örneğin, bir modelin eğitimi yüksek bir doğruluk oranına ulaştıktan sonra, modelin kaydedilmesi ve daha sonra yeniden kullanılması mümkündür.
Sonuç olarak, modellerin kaydedilmesi, bir modelin gelecekteki kullanımları için hazır hale getirilmesine yardımcı olan önemli bir adımdır.
CNN Mimarileri Nedir?
Konvolüsyonel sinir ağları (CNN’ler), görüntü işlemede ve sınıflandırmada başarıyla kullanılan bir derin öğrenme yöntemidir. CNN’lerin temel amacı, görüntülerdeki özelliklerin çıkarılması ve ardından bu özelliklerin kullanılarak doğru sınıflandırma yapılmasıdır.
CNN’ler, genellikle birkaç konvolüsyonel katman, aktivasyon fonksiyonları, havuzlama katmanları ve tam bağlantılı katmanlardan oluşur. Konvolüsyonel katmanlar, görüntüdeki özellikleri belirlemek için bir dizi filtre kullanır. Filtreler, görüntünün farklı bölümlerindeki pikseller arasında matematiksel işlemler yaparak özellikleri çıkarır. Aktivasyon fonksiyonları, filtrelerin çıkardığı özellikleri birbirine bağlar ve çıktıları “aktive” ederek sinir ağına devam etmek için hazırlar.
Havuzlama katmanları, görüntü boyutunu azaltırken önemli özelliklerin korunmasını sağlar. Bu, sinir ağının daha az sayıda parametreye sahip olmasına ve daha hızlı çalışmasına olanak tanır. Tam bağlantılı katmanlar, sinir ağının son çıktısıyla sınıflandırma yapmak için kullanılır.
CNN’ler, farklı derinliklerde ve karmaşıklıkta farklı mimarilere sahip olabilir. Örneğin, VGGNet, çok sayıda küçük boyutlu filtreleri kullanarak görüntü özelliklerini çıkarmak için daha derin bir mimari kullanırken, ResNet, daha derin bir ağın overfitting sorununu çözmek için blok yapıları kullanır.

Sonuç olarak, CNN’ler, derin öğrenmenin önemli bir alanıdır ve geniş bir uygulama yelpazesine sahiptir. Görüntü sınıflandırması, nesne tanıma, yüz tanıma, doğal dil işleme gibi alanlarda başarılı sonuçlar vermektedir.
CNN Mimarileri Nelerdir?
CNN mimarileri, birbirinden farklı katmanlardan oluşan, derin öğrenme modelleridir. Bu katmanlar, girdi verisini işleyerek, özellik çıkarmak ve sınıflandırma yapmak için kullanılır. CNN mimarileri, özellikle görüntü işleme alanında sıkça kullanılır.
CNN mimarilerinde kullanılan katmanlar arasında genellikle evrişim (convolutional), havuzlama (pooling), normalleştirme (normalization) ve tam bağlantı (fully-connected) katmanları bulunur. Bu katmanlar, farklı özellikleri çıkarmak, boyutu azaltmak, ağırlıkları öğrenmek ve son sınıflandırma için kullanmak gibi işlemleri gerçekleştirir.
Örnek olarak, AlexNet, VGG, ResNet, Inception ve DenseNet gibi popüler CNN mimarileri bulunmaktadır. Bu mimariler, farklı sayıda katmanlar ve parametreler kullanarak, farklı boyutlardaki veriler üzerinde iyi sonuçlar vermektedir.
CNN mimarilerinin avantajları arasında özellikle görüntü işleme alanında yüksek performans ve özellik çıkarma yetenekleri, veri büyütme teknikleri ve ölçeklenebilirlik sayılabilir. Ancak, daha karmaşık modellerin eğitilmesi daha uzun sürebilir ve daha fazla hesaplama gücü gerektirebilir.

Bazı popüler CNN mimarileri şunlardır;
1-)LeNet-5: 1998 yılında Yann LeCun tarafından tanıtılan ve ilk başarılı CNN modeli olan LeNet-5, özellikle el yazısı rakamlarının sınıflandırılması için tasarlanmıştır.
2-) AlexNet: 2012 yılında Alex Krizhevsky tarafından tanıtılan AlexNet, ImageNet veri kümesindeki 1.2 milyon görüntüden oluşan 1,000 sınıflı bir sınıflandırma görevini gerçekleştirdi ve büyük bir başarı elde etti. AlexNet, derin öğrenme alanında çığır açtı ve daha sonra birçok farklı uygulamada kullanıldı.
3-)VGG: 2014 yılında Visual Geometry Group (VGG) tarafından tanıtılan VGG mimarileri, farklı derinliklere sahip birçok farklı varyasyona sahiptir. Bu mimariler, daha fazla katman kullanarak daha yüksek performans elde etmeyi amaçlar.
4-)GoogLeNet: 2014 yılında Google tarafından tanıtılan GoogLeNet, Inception mimarisi olarak da bilinir. Bu mimari, daha hafif ve daha az parametreli modeller için tasarlanmıştır.
5-)ResNet: 2015 yılında Microsoft tarafından tanıtılan ResNet, son derece derin modeller için tasarlanmıştır ve aşırı uyum (overfitting) sorunlarını önlemek için “skip connections” olarak da bilinen bağlantılar kullanır.
Inception ile Resimdeki Objeleri Tanıma Nedir?
Inception, Google tarafından geliştirilmiş bir sinir ağı mimarisi ve görüntü sınıflandırma modelidir. Bu model, Convolutional Neural Network (CNN) mimarilerinin performansını artırmak için tasarlanmıştır ve özellikle görüntü sınıflandırma alanında büyük bir başarı elde etmiştir. Inception, girdi olarak aldığı görüntülerin farklı özelliklerini ayrı ayrı ele alarak farklı ölçeklerde filtreler kullanır. Böylece, model, görüntüdeki farklı nesne türlerini daha iyi tanımlayabilir.
Inception’ın temel fikri, girdi görüntüsündeki farklı özelliklerin farklı filtreler tarafından ele alınmasıdır. Ancak, bu yöntem geleneksel CNN mimarilerinde aşırı hesaplama maliyetine neden olabilir. Bu nedenle, Inception, modellerin daha verimli hale getirilmesi için çeşitli yenilikler içerir. Örneğin, Inception modeli, “1×1 convolution” adı verilen küçük boyutlu filtreleri kullanarak, girdi görüntüsündeki farklı özellikleri daha verimli bir şekilde ele alır. Ayrıca, modeldeki farklı blokların paralel işlenmesi, daha hızlı bir hesaplama süreci sağlar.
Inception modeli, nesne tanıma, yüz tanıma ve doğal dil işleme gibi alanlarda kullanılmaktadır. Bununla birlikte, model, doğruluk oranını daha da artırmak için çeşitli iyileştirmeler yapılarak, farklı versiyonları da geliştirilmiştir. Bu versiyonlar, daha yüksek doğruluk oranları elde etmek için farklı yöntemler kullanır ve farklı filtre boyutları, adım boyutları, blok yapıları ve düzenleme teknikleri gibi farklı parametrelerle ayarlanabilir.

Transfer Learning Nedir?
Transfer Learning, bir makine öğrenimi modelinin, önceden eğitilmiş bir modelin özelliklerini kullanarak başka bir görev için yeniden kullanılmasıdır. Bu yaklaşım, bir modelin eğitim verilerinin sınırlı olduğu veya eğitim için gereken hesaplama kaynaklarının yetersiz olduğu durumlarda faydalı olabilir.
Transfer Learning, genellikle bir önceden eğitilmiş modelin büyük bir veri kümesinde eğitilmesi ve ardından yeni bir görev için kullanılabilen özellikler öğrenmesiyle gerçekleştirilir. Bu özellikler daha sonra, yeni bir modelin eğitimi sırasında kullanabilmekte ve bu, yeni görev için daha az veri gerektirir ve daha hızlı bir eğitim süreci sağlar.
Önceden eğitilmiş modeller, genellikle görüntü sınıflandırma, nesne tespiti veya doğal dil işleme gibi alanlarda kullanılmaktadır. Örneğin, bir görüntü sınıflandırma modeli, birçok farklı nesne türünü tanımak için eğitilmiş olabilir. Bu model, daha sonra nesne tespiti veya görüntü segmentasyonu gibi başka bir görev için kullanılabilir, çünkü bu görevler de görüntü sınıflandırmaya benzer özellikler taşır.
Transfer Learning, derin öğrenme alanında oldukça yaygın bir tekniktir ve özellikle sınırlı veri setleri veya donanım kısıtlamaları nedeniyle yeni modellerin eğitiminde faydalıdır. Bu teknik, modelin daha hızlı eğitilmesini, daha yüksek doğruluk oranlarını ve daha az hesaplama kaynağı kullanımını mümkün kılarak, özellikle endüstriyel ve ticari uygulamalarda büyük bir avantaj sağlar.
Görsel Analiz Nedir?
Görsel analiz, bilgisayarın dijital görüntüleri anlamasına ve yorumlamasına olanak tanıyan bir makine öğrenimi alanıdır. Görsel analiz, görüntü işleme, modelleme ve çıkarım yapma teknikleri kullanarak, dijital görüntülerdeki nesneleri ve özellikleri tanımlamayı amaçlar.
Görsel analiz, genellikle görüntü sınıflandırma, nesne tespiti, yüz tanıma, duygusal analiz ve optik karakter tanıma gibi farklı görevler için kullanılır. Bu görevler, farklı makine öğrenimi teknikleri kullanılarak gerçekleştirilir.
Örneğin, bir görüntü sınıflandırma algoritması, bir görüntüdeki nesnenin hangi sınıfa ait olduğunu belirleyebilir. Nesne tespiti algoritmaları ise, bir görüntüdeki nesneleri sınır kutularıyla işaretleyebilir.
Görsel analiz, endüstriyel otomasyon, tıbbi görüntüleme, robotik, güvenlik, otomotiv ve eğlence endüstrisi gibi birçok alanda kullanılır.
Örneğin, araçlar için geliştirilen görüntü işleme teknikleri, sürüş güvenliğini artırmaya yardımcı olurken, tıbbi görüntüleme teknolojileri, doktorların hastaların teşhis ve tedavisinde yardımcı olmasına imkan sağlar.
Görsel analiz, insan gözüne benzer bir şekilde dijital görüntülerin içeriğini anlama yeteneği sağlar ve bu nedenle, bilgisayarların daha akıllı ve insanlara daha yakın hale gelmesine yardımcı olan önemli bir makine öğrenimi alanıdır.
Deep Dream Nedir?
Deep Dream, Google tarafından geliştirilen bir görüntü sentezleme tekniğidir. Bu teknik, bir yapay sinir ağı modeli olan Convolutional Neural Network (CNN) kullanarak, bir görüntüdeki özellikleri belirlemek ve vurgulamak için tasarlanmıştır.
Deep Dream, CNN modellerinin belirli katmanlarında oluşan aktivasyonları manipüle ederek, bir görüntüdeki belirli özelliklerin vurgulanmasını sağlar. Bu vurgulama işlemi, görüntünün farklı bölgelerindeki piksellerin değerlerindeki değişikliklerle gerçekleştirilir ve sonuçta, ilginç ve hayali görüntüler elde edilir.
Bu teknik, özellikle sanatçılar ve görsel efektler tasarımcıları tarafından kullanılmaktadır. Örneğin, Deep Dream, bir fotoğraftaki desenleri, şekilleri ve renkleri vurgulayarak, özgün ve ilginç görsel efektler oluşturabilir. Ayrıca, bu teknik, CNN modellerinin farklı katmanlarında oluşan aktivasyonların incelenmesi için de kullanılabilir ve bu da derin öğrenme modellerinin çalışması hakkında daha fazla bilgi sağlayabilir.
Deep Dream, ilginç ve eğlenceli görseller oluşturma potansiyeli nedeniyle popüler bir teknik olmasına rağmen, daha geniş bir uygulama alanına sahip değildir. Bunun nedeni, Deep Dream’in, sadece görsel sentezleme için tasarlanmış olması ve gerçek dünya uygulamalarında pek kullanışlı olmamasıdır.